Liebe Besucher der verschiedensten Geschlechter,
liebe Frauen, liebe Männer und liebe Diverse,
– was für eine ungewöhnliche Art der Anrede, oder?
Ja, das finden wir auch! Denn welche Rolle sollte Ihr Geschlecht beim Besuch dieser Seiten spielen? Richtig, es spielt gar keine Rolle!
Wir haben uns deshalb entschlossen, in unserer Kommunikation nicht zu gendern und auch nicht explizit einzelne Geschlechter in einer Aufzählung anzusprechen – denn Gendern geht für uns mit Ausschluss und nicht mit Inklusion einher: von Besucher*innen (oder Besucher und Besucherinnen) zu sprechen, grenzt sprachlich ganz bewusst diejenigen aus, die sich dem männlichen oder weiblichen Geschlecht, aus welchen Gründen auch immer, nicht zugeordnet fühlen.
Gendern fördert, in unseren Augen, gedanklich ganz bewusst, die Verknüpfung einer Person mit ihrem biologischen Geschlecht.
Wenn wir von einem Besucher sprechen, dann meinen wir nicht männliche oder weibliche Besucher (sonst würden wir das so schreiben!), sondern ganz allgemein Besucher unabhängig von ihrem Geschlecht. Es spielt für uns auch keine Rolle, welchem Geschlecht sich eine Person zuordnet. Besucher sind Lebewesen, die auf unseren Seiten vorbeischauen und auf diese Weise adressiert werden. Und dieses Prinzip gilt bei uns gleichermaßen für die Softwareentwickler, die Pflegekräfte, die Autofahrer, die Erzieher, die Flugbegleiter, etc. (wir verwenden hier absichtlich den Pluralartikel, um etwas zu veranschaulichen, auf das wir gleich eingehen werden ![]() ).
).
Uns ist bewusst, dass nun augenscheinlich eine Konfliktsituation entsteht (die eigentlich keine ist); deshalb ein kurzer Exkurs:
Die deutsche Sprache unterscheidet Nomen nach ihrem Genus, dem grammatischen Geschlecht, mit seinen drei Formen: maskulin, feminin und neutrum – gekennzeichnet durch die Artikel "der", "die", "das". Das Genus ist nicht zu verwechseln mit dem Sexus – der Ausprägung des natürlichen Geschlechts, das in der deutschen Sprache zwei Formen kennt: männlich oder weiblich. Genus und Sexus haben nichts miteinander zu tun, weshalb unterschiedliche Genera, für Objekte (zum Beispiel: der Tisch (maskulin), die Theke (feminin), das Besteck (neutrum)) ganz offensichtlich unabhängig von biologischen Eigenschaften und auch – trotz vermeintlicher Parallelen zum biologischen Geschlecht – unabhängig vom Sexus, verwendet werden (zum Beispiel: der Busen und der Uterus (maskulin), die Eichel und die Prostata (feminin), das Glied und das Spermium (neutrum)).
Berufsbezeichnungen im Singular haben historisch bedingt oft das grammatisch maskuline Geschlecht, wenn ein Beruf früher typischerweise von einem Mann ausgeübt wurde und das Feminine, wenn es sich typischerweise um einen "Frauenberuf" gehandelt hat – ja, unsere Sprache ist da klischeebehaftet und sexistisch oder sie spiegelt einfach gewöhnliche Lebensumstände wider. Gäbe es diese sprachliche Unterscheidung nicht, wäre uns das Thema "Gendern" vermutlich erspart geblieben; aber so funktioniert unsere Sprache nunmal. Auch ist unsere Sprache in der Pluralbildung nicht vollständig konsistent:
- der Student, die Studentin, die Studenten
- der Pilot, die Pilotin, die Piloten
- jedoch der Softwareentwickler, die Softwareentwicklerin, aber die Softwareentwickler__.
der Pfleger, die Pflegerin, aber die Pfleger__.
der Autofahrer, die Autofahrerin, aber die Autofahrer__.
Die Pluralform sieht also manchmal nach einem Maskulinum aus und wird deshalb auch als das generische Maskulinum bezeichnet. Generisch deshalb, weil es sich eben gerade auf eine ganze Gruppe von Personen, ohne weitere Differenzierung, bezieht.
Viel wichtiger ist, was im Kopf passiert:
Wenn wir unter Softwareentwicklern Personen verstehen, die Software entwickeln und eben kein stereotypes Bild im Kopf haben, von männlichen Nerds in ihren Mittzwanzigern mit Kapuzenpullis, dann – ja dann, verstehen wir uns.
Wer vornehmlich stereotyp denkt und damit gedanklich ausgrenzt bzw. sich selbst ausgegrenzt fühlt oder fühlen möchte, dem empfehlen wir, sein eigenes Weltbild der Moderne anzupassen.
Und wer Genus und Sexus nicht unterscheiden kann, dem empfehlen wir, sich intensiver mit der deutschen Grammatik auseinanderzusetzen.
Wer anschließend in der Verwendung eines generischen Maskulinums einen Sexismus sieht, entlarvt damit seine Ideologie und das bloße Unterstellen einer vermeintlichen Meinung.
Das Nicht-Gendern hat also viele Vorteile, denn plötzlich erhalten wir echte Gleichstellung und Gleichbehandlung, weil wir eben nicht mehr in biologischen Geschlechtern (oder anderen personenbezogenen Merkmalen, wie Alter, ethnischer Herkunft, Weltanschauung oder Behinderung) denken oder grammatische Eigenschaften unsinnigerweise auf biologische bzw. natürliche Geschlechter projizieren.
Um beim Beispiel des Softwareentwicklers zu bleiben:
- Wenn wir in der Kommunikation beim Angesprochenen das Bild einer ausdrücklich männlichen Person zeichnen wollen, sprechen wir von einem männlichen Softwareentwickler.
- Wenn wir das Bild einer ausdrücklich weiblichen Person zeichnen möchten, dann sprechen wir von einem weiblichen Softwareentwickler oder einer Softwareentwicklerin.
- Wenn wir das Bild einer transgeschlechtlichen, indisch-stämmigen, hinduistischen Person, ohne körperliche Einschränkungen, in ihren Mittzwanzigern vermitteln möchten, dann benennen wir eben diese Attribute.
Wenn wir jedoch nur von einem Softwareentwickler sprechen, dann haben wir explizit keine Vorstellung in Bezug auf das Geschlecht (oder sonstige Eigenschaften, die über die Fähigkeit Software zu entwickeln hinausgehen).
Dieser Artikel wird laufend aktualisiert und um Empfehlungen/Best-Practices erweitert.
Vorwort
Die Verfügbarkeit von Kommunikationsdiensten ist für viele Unternehmen von höchster Priorität. Mit dem Wandel der Kommunikationsnetze von TDM zu IP-basierten Next Generation Networks (NGN) und der Möglichkeit, die Kommunikationsdienste virtualisiert – in Form gewöhnlicher Serverdienste – bereitzustellen, ergeben sich neue Möglichkeiten der Hochverfügbarkeit und Skalierbarkeit.
Wurden bisher meist Aktiv/Passiv-Gerätekonfigurationen verwendet, um den Ausfall eines Primärgeräts abzusichern, stehen heute verschiedene Redundanzszenarien zur Verfügung, die die unterschiedlichen Anforderungen an Service-Level und eventuelle Wiederherstellungszeiten im Disaster Recovery-Fall abdecken.
Die Bereitstellung von Kommunikationsdiensten in Form von IT-Diensten ist deshalb nicht nur der logische Schluß aus der Konvergenz der Daten- und Kommunikationsnetze, sondern auch das Mittel der Wahl, um hohe Verfügbarkeit und einfaches bzw. einheitliches Management zu garantieren.
Ein virtualisiertes Kommunikationssystem skaliert nicht nur mit den zur Verfügung gestellten Ressourcen, sondern läßt sich auch in vorhandene Backup- oder Disaster-Recovery-Strategien integrieren: Backups, Snapshots, Replikationen, Fault Tolerance und weitere Technologien erlauben es unter Abwägung von Ressourceneinsatz und Komplexität die geforderte Verfügbarkeit zu erreichen. Dabei lassen sich bereits etablierte Strategien, Richtlinien und Notfallkonzepte unmittelbar auf den Kommunikationsdienst anwenden, was die Komplexität und damit Anwenderfehler reduziert und im Fall der Fälle eine schnelle Wiederherstellung der unternehmenskritischen Anwendung ermöglicht.
STARFACE Plattformen & STARFACE Flip
Das STARFACE Kommunikationssystem basiert auf einem CentOS Linux System, auf dem unter anderem der STARFACE Applikationsserver (auf Basis von tomcat), der HylaFax Faxserver und der CallHandler Asterisk Business Edition arbeiten.
Da es sich technisch gesehen also um ein Linux-Serversystem handelt, ist es wenig verwunderlich, dass STARFACE auch auf den typischen IT-Diensteplattformen "Appliance", "Cloud" und "VM" betrieben wird.
Die VM-Edition enthält Integrationstreiber für VMware und Hyper-V und ist ansonsten identisch mit der auf Appliances oder in der Cloud installierten STARFACE Software.
STARFACE Flip beschreibt die Möglichkeit, jederzeit von einer Plattform auf eine andere zu wechseln. Hierfür muß lediglich eine Serverlizenz für die Zielplattform vorhanden sein. Benutzer- und Feature-Lizenzen lassen sich beliebig übertragen – ebenso wie die Konfiguration und Daten (Ruflisten, Voicemails, Faxe, etc.).
Vorteile der TK-Virtualisierung
Im folgenden Abschnitt beleuchten wir Gründe, warum es von Vorteil ist, STARFACE primär virtualisiert zu betreiben.
Qualität der eingesetzen Hardware
Es ist nicht unüblich, dass Unternehmen deutlich mehr in in Ihre IT-Landschaft bzw. Server-Infrastruktur investieren, als in die Hardware einer Telefonanlage. Die Server- und Netzwerk-Infrastruktur ist für die Bereitstellung von Geschäftsanwendungen und für die Aufrechterhaltung des Geschäftsbetriebs verantwortlich und hat daher – wenig überraschend – einen hohen Stellenwert.
In mittelständischen Unternehmen und erst recht im Enterprise-Umfeld finden sich daher typischerweise:
- Hochverfügbare Cluster, bestehend aus mehreren Servern an unterschiedlichen Standorten
- Markenserver mit hochwertigen und für höchste Verfügbarkeit ausgelegten elektronischen Bauteilen
- Server-Virtualisierung mit HA-Mechanismen
- Fehlererkennender und -korrigierender Speicher (ECC-Speicher)
- Hochverfügbare und redundant per Multi-Pathing angebundene SANs, basierend auf Disk-Arrays in RAID-Verbünden, mit wiederum redundanten Anbindungen einzelner Hot-Swap SSDs/HDDs an unterschiedliche Host-Adapter (Dual-Port SAS) und Server-SSDs/HDDs mit erhöhter Ausfallsicherheit und geringeren Lesefehlerraten
- Redundante und hot-swap-fähige Netzteile und Lüfter, redundante und unterbrechungsfreie Stromversorgung (USV)
- Aktive Klimatisierung
- Link-aggregierte Netzwerkverbindungen
- Hochwertige Verkabelung (Klasse EA Twisted-Pair oder LWL)
- Hardware-Monitoring und Auslastungsüberwachung
- Backup- und Disaster-Recovery-Konzepte; Off-Site-Backups
Typische TK-Systeme sind im Gegensatz dazu meist sehr einfach gestrickt. Redundanz bedeutet hier meist, identische Hardware vorzuhalten und im Besten Fall in einem Aktiv-/Passiv-Verbund zu betreiben. In Form reiner Hardware-Investitionskosten (Endgeräte ausgenommen) liegen typische TK-Systeme deshalb oft zwischen einem Zehntel und einem Hundertstel der IT-Hardwareinvestitionen.
Bei der Bereitstellung von Kommunikationsdiensten in Form von IT-Diensten läßt sich jedoch von der Qualität und Verfügbarkeit der IT-Infrastruktur profitieren – indem die TK als virtualisierter Dienst auf dieser Infrastruktur ausgeführt wird.
Skalierbarkeit

Vor der Anschaffung eines neuen TK-Systems stellt sich in der Regel die Frage nach der Dimensionierung. Sollen 50, 100, 500 oder über 1.000 User das System nutzen? Welche Annahmen können bezüglich der gleichzeitigen Nutzung bzw. Spitzenlasten getroffen werden? Welche zusätzlichen Funktionen soll das System unter Umständen in Zukunft mit übernehmen?
Die Empfehlung "Nehmen Sie eine Größe größer, Sie wachsen schon rein", soll hier vorhandene Unsicherheiten durch Schaffung eines "Puffers" berücksichtigen.
Genau diese Überlegungen haben Unternehmensentscheider bereits bei der Dimensionierung der IT-Infrastruktur (hoffentlich) berücksichtigt, so dass in der Regel ausreichend Leistungsreserven vorhanden sind um das zu erwartende Wachstum der nächsten Jahre aufzufangen. Die TK-Virtualisierung erlaubt es, diese Leistungsreserven bei Bedarf zu nutzen. Wenn Mitarbeiterzahlen anwachsen oder weitere Standorte hinzukommen, bedeutet das für den Betrieb des TK-System in der Regel einfach nur das Zuweisen von etwas mehr Arbeitsspeicher, Storage und vielleicht eines weiteren CPU-Kerns. Das System skaliert mit den zur Verfügung gestellten Ressourcen.
Wiederherstellbarkeit
Durch die Abstraktion physikalischer Hardware sind virtualisierte Systeme prinzipiell unabhängig von der konkreten Betriebsumgebung und lassen sich ohne Weiteres auf andere Serverhardware migrieren. Der unter Umständen schwierige oder zeitaufwändige Vorgang, kompatible Austauschhardware zu beschaffen entfällt.
Auch ist die Wiederherstellbarkeit einer kompletten VM mit gängigen Backup- und Disaster-Recovery-Tools nur noch eine Frage weniger Mausklicks.
Vor Änderungen der Konfiguration oder Systemupdates läßt sich in Sekundenschnelle ein VM-Snapshot anlegen, der ebenso schnell wieder zurückgespielt werden kann. So verlieren Updates oder Konfigurationsänderungen ihren Schrecken. Auf physikalischer Hardware wäre für ein Downgrade nach einem Update eine aufwendige Neuinstallation notwendig.
Betriebswirtschaftliche Aspekte
Die Anschaffung physikalischer TK-Systeme bedeutet im Rahmen der Budgetplanung für die ITK-Verantwortlichen auch die Berücksichtigung möglicher Defekte, Reparaturen oder Neuanschaffungen von Hardware nach Ablauf von Garantie- und Gewährleistungszeiträumen (die in der Regel deutlich kürzer sind als die zu erwartende Nutzungsdauer; Annahme nach AfA-Tabelle: 10 Jahre). Darüber hinaus muss die Ersatzteilverfügbarkeit sichergestellt und notfalls Ersatzteile bevorratet werden.
Ein virtualisiertes System, welches prinzipiell nur noch aus Lizenzen (also aus Nutzungsrechten an einer Systemsoftware) besteht, birgt keine Risiken eines Defekts und ist in der Nutzungsdauer uneingeschränkt. Über entsprechende Updateverträge läßt sich ein System, welches gänzlich aus Software besteht, dauerhaft auf einem aktuellen Stand halten – ganz ohne alternde Hardware.
Ansonsten ergeben sich natürlich noch die ganz typischen Kostenvorteile der Virtualisierung: Einsparungen in Bezug auf die anzuschaffende TK-Hardware, Strom, Kühlung, Rackspace, Netzwerkports und geringere Personalkosten aufgrund administrativer Vorteile.
Lokale Redundanz
Lokale Redundanz kann über Funktionen wie VMware Fault Tolerance (FT) erreicht werden. Hierbei wird eine identische STARFACE-Instanz synchron innerhalb des VMware-Clusters ausgeführt (Active Secondary). Der Ausfall eines physikalischen Hosts wird automatisch und unterbrechungsfrei kompensiert.
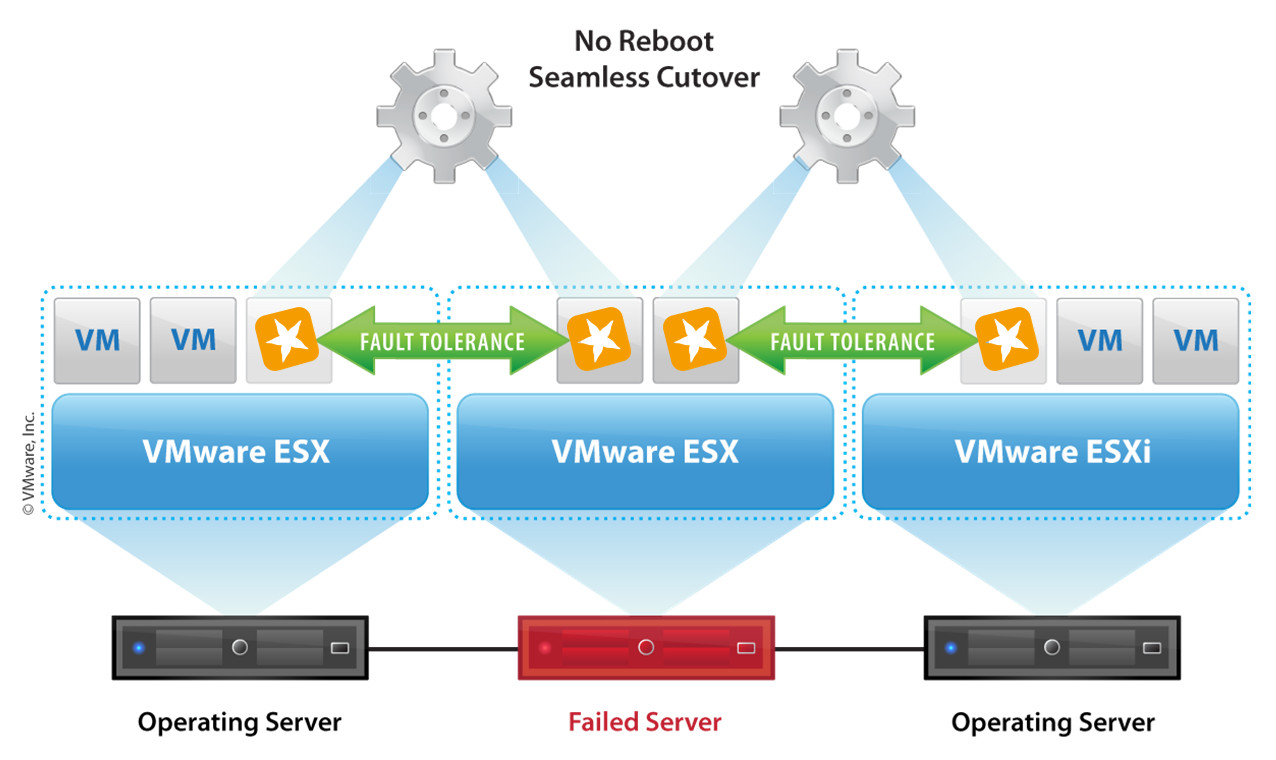
Hyper-V
Eine ähnliche Hochverfügbarkeitsfunktion für lokale Redundanz steht auch In Hyper-V-Umgebungen mit Hyper-V Live Migration zur Verfügung.
Geo-Redundanz
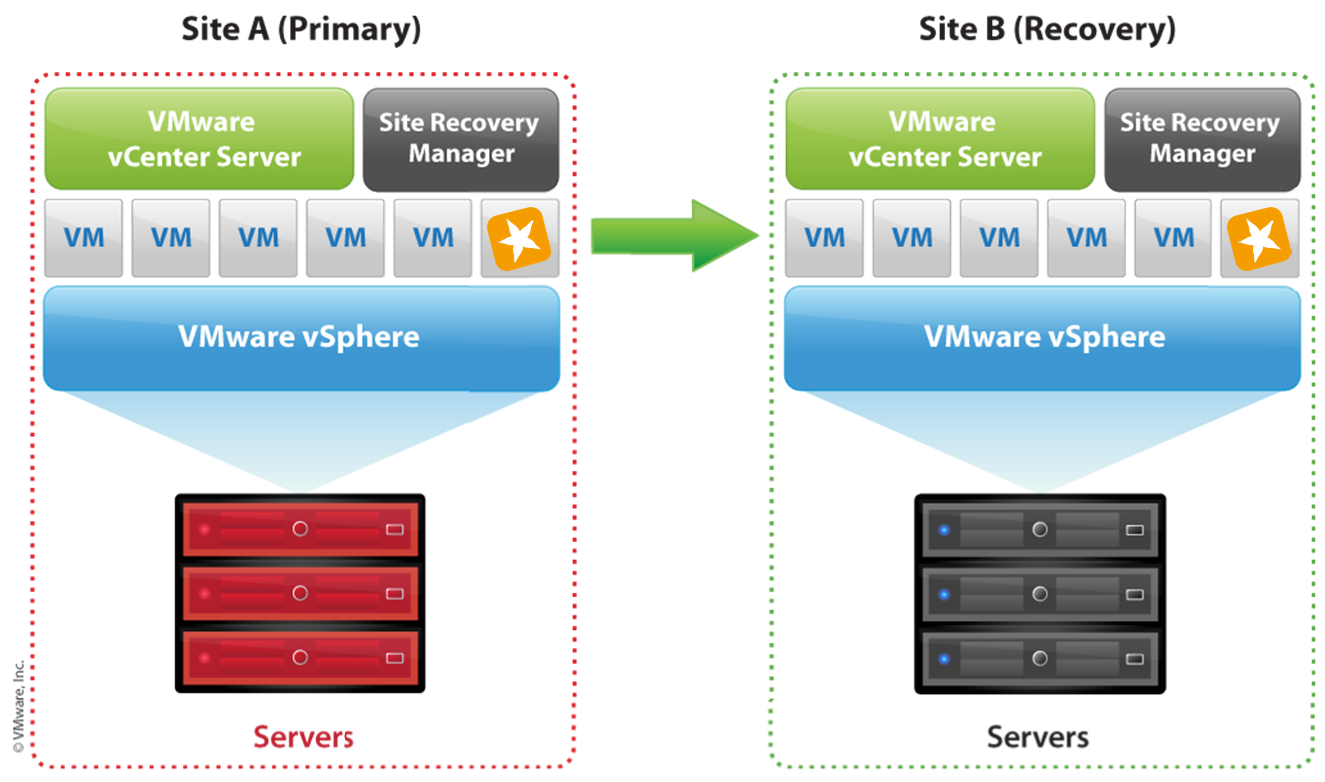 Bei der geografischen Redundanz, werden die Standorte in einen Hauptstandort, Sekundärstandort und vielleicht sogar einen Tertiärstandort unterteilt. Ein Sekundärstandort stellt den Betrieb des STARFACE Kommunikationssystems sicher, sollte der Primärstandort ausfallen. Der Tertiärstandort stellt den Betrieb bei Ausfall von Primär- und Sekundärstandort sicher.
Bei der geografischen Redundanz, werden die Standorte in einen Hauptstandort, Sekundärstandort und vielleicht sogar einen Tertiärstandort unterteilt. Ein Sekundärstandort stellt den Betrieb des STARFACE Kommunikationssystems sicher, sollte der Primärstandort ausfallen. Der Tertiärstandort stellt den Betrieb bei Ausfall von Primär- und Sekundärstandort sicher.
Hierfür kommen die Funktionen des VMware Site Recovery Managers (SRM) zum Einsatz: Im Falle eines Ausfalls des primären Standorts, werden Replikate der STARFACE VM-Edition am sekundären oder tertiären Standort gestartet.
Ein Failover auf geo-redundanter Basis ist in der Regel nicht unterbrechungsfrei, sondern geht meist mit einem Abbruch laufender Gespräche und einem Ausfall der Telefoniefunktion im Bereich von Sekunden bis wenigen Minuten einher. Die Ausfallzeit wird hauptsächlich durch die Konvergenz des jeweils eingesetzten IP-Routingprotokolls bestimmt. Auf Router-Ebene müssen die Verbindungen der Endgeräte/Clients und Mediengateways zur sekundären oder tertiären STARFACE VM (mit identischer IP-Adresse) an einem anderen Standort geroutet werden. Bei Einsatz von OSPF mit BFD können die Konvergenzzeiten jedoch stark reduziert werden.
Wichtig ist, dass die STARFACE VMs an den weiteren Standorten mit identischer IP-Adresskonfiguration starten. Hierfür sollte ein separates Netz angelegt werden. Nur so ist sichergestellt, dass sich die Endgeräte unverzüglich nach Verfügbarwerden der Redundanz-VMs an diesen Anmelden. Die "Umschaltung" auf die Geo-Redundanzanlagen ist somit auf die Ebene des Netzwerk-Routings verlagert.
Hyper-V
Eine ähnliche Hochverfügbarkeitsfunktion für Geo-Redundanz steht auch In Hyper-V-Umgebungen mit Hyper-V Replicas zur Verfügung. Die RPO ist ab Windows Server 2012 konfigurierbar (30 Sekunden, 5 Minuten oder 15 Minuten).
Bei der Telefonie über WLAN (nach 802.11) gibt es grundlegende Unterschiede im Vergleich zu DECT.
DECT wurde ursprünglich für die Telefonie entwickelt, WLAN für die Datenkommunikation. Hieraus ergeben sich wichtige Unterschiede in Bezug auf die Dienstgüte. DECT ist optimiert auf minimale Verzögerung und gleichbleibende Verbindungsqualität bei geringem Stromverbrauch. Bei WLAN sind diese Parameter abhängig von der Anzahl, Art und Signalstärke von WLAN-Endgeräten.
Physikalische Eigenschaften und Medienzugriff
Das 2,4GHz Band, das von WLAN nach 802.11b verwendet wird (aber auch das 5GHz Band für WLAN nach 802.11a) gehört zum ISM-Band für die Allgemeinnutzung.
Im 2,4GHz-Bereich tummeln sich neben WLAN (802.11b), Bluetooth, ZigBee, Mikrowellenherden, Radargeräten und CO2-Lasern auch Funkfernsteuerungen und allerhand weitere "Allgemeinnutzer". Physikalisch nutzbar ist ein Kanal immer nur von einem Sender/Empfänger. Die Geräte wechseln sich also ab.
Im 5GHz Band ist militärisches Radar Primärnutzer. WLAN, drahtlose Videoübertragungssysteme und andere ISM-Band-Nutzer sind Sekundärnutzer, die dafür Sorge tragen müssen, dass Primärnutzer nicht gestört werden. In 802.11a und 802.11h wurden deshalb Funktionen implementiert (DFS, TPC, ...), die dafür sorgen, dass bei Erkennung von Radar das WLAN-System einen Kanalwechsel durchführt. Da die neuen Kanäle auf Radar geprüft werden müssen, kann ein solcher Kanalwechsel durchaus bis zu mehrere Minuten dauern – während dieser Zeit ist die WLAN-Verbindung unterbrochen (Außenanbindungen/Richtfunkstrecken sind hiervon immer mal wieder betroffen). Durch das fast 300 MHz breite Band haben Kanalwechsel außerdem Auswirkungen auf die Streckendämpfung.
Das europäische DECT-Band befindet sich deutlich unterhalb des für die Allgemeinnutzung freigegeben ISM-Bands, im Bereich zwischen 1,8–1,9GHz. Hier gibt es also keine Störung durch andere ISM-Band-Nutzer.
Der WLAN-Physical Layer verwendet für den Medienzugriff CSMA/CA (Carrier Sense Multiple Access with Carrier Avoidance). Alle Nutzer verwenden den selben Kanal und versuchen Kollisionen zu vermeiden, indem sie den Kanal belauschen und zufällige Zeiträume abwarten (sog. Interframe Spacing Zeiten).
Wenn es zu Kollisionen kommt, wird ein "Backoff" gemacht und erneut eine zufällige Zeit gewartet.
Ohne auf die genauen Details einzugehen ist das Ergebnis ein Medienzugriff, der mit steigender Anzahl der Endgeräte ein immer schlechteres Zugriffsverhalten besitzt. Vor allem ist es zeitlich nicht deterministisch. Bis zum Punkt, an dem ein WLAN-Gerät zwar das Netzwerk "sieht", mit diesem aber nicht mehr kommunizieren kann.
Die verfügbare Kapazität wird bei WLAN von allen WLAN-Geräten und Mitnutzern des selben Bands beansprucht.
DECT funktioniert hier anders: Die Kapazität steht ausschließlich der Telefonie zur Verfügung. Der Medienzugriff erfolgt über ein Frequenz- und Zeitslot-Verfahren (2-dimensionale Spektrumteilung), bei dem sich zwar nur eine begrenzte aber definierte Anzahl an Geräten mit einer Basis verbinden können, weitere Geräte stören den Betrieb nicht. Die Dienstgüte ist gewahrt. Für die kalkulierte Anzahl an Geräten ist die Telefonie auf jeden Fall möglich.
Beim Aufbau von WLAN-Netzen ist darüberhinaus darauf zu achten, dass die Frequenzbereiche der benachbarten AccessPoints disjunkt sind und ausreichend große räumliche Überlappungsflächen bilden -- im europäischen 2,4 GHz Band ist da bei drei benachbarten APs Schluß.
Bei zu kleinen Überlappungsflächen gibt es Probleme beim Wechsel der Funkzelle, bei zu großen Überlappungsbereichen wird man kaum disjunkte Frequenzbereiche schaffen, was zur Sättigung des Mediums führt und die Kapazität verringert.
Data-Link-Layer / Verbindungseigenschaften
DECT bietet echtes Roaming und einen unterbrechungsfreien Handover, bei dem während des Handover-Vorgangs zwei parallele Links zu den Basisstationen aufgebaut werden und auf beiden Links die gleichen Sprachinformationen übertragen werden.
Außerdem erlaubt DECT echten Full-Duplex-Betrieb (durch TDD (Time Division Duplex)).
WLAN kennt keinen Full-Duplex-Betrieb. Außerdem wechselt das Gerät die Zelle, wenn die Verbindung zum ersten AP zusammenbricht oder ein besserer AP gleicher SSID vorhanden ist. Es folgt dabei ein erneuter Anmeldevorgang am neuen AP. Sobald die ersten Pakete über den neuen AP gehen bekommt das die Switching-Infrastruktur im Hintergrund mit und aktualisiert die MAC-Tables – unterbrechungsfrei geht anders.
Die IAPP-Funktion (z.B. bei Cisco oder Lancom oder nach 802.11f, welches jedoch wieder zurückgezogen wurde) sorgt außerdem nicht für ein unterbrechungsfreies Handover. Es wird nur mit Hilfe von Multicast IAPP-Packeten der Security Context zwischen APs übergeben und die Stationstabelle aktualisiert. Grund ist der 802.11-Standard (Kapitel 5.4.2.2, 802.11-2007), der zwingend vorschreibt, dass eine Station zu jeder Zeit immer mit maximal einem AP assoziiert ist. Es gibt hier also immer eine Reassoziierungs-Phase, sprich: Verbindungsabbau und Neuaufbau.
Diese gehen zwar in der Regel schnell vonstatten, das konkrete Timing hängt aber von mehreren Parametern ab: Anzahl der Clients im Netz, Geschwindigkeit des Clients, Geschwindigkeit des AP, Latenz für die Authentifizierung (u.U. Radius-Kommunikation).
Gerade bei der Sprachkommunikation per UDP gehen während der Reassoziierungs-Phase Pakete unweigerlich verloren. Bei vorhandener Verbindungssicherung (TCP) hängt es von der Zeitdauer der Reassoziierung und Größe der Dejitter-Buffer in den Endgeräten ab, ob die Verluste hörbar sind.